
A protocol buffer is a platform and language-neutral automated mechanism for serializing structured data. A protocol buffer is smaller, simpler and faster than XML. As per the doc:
“Protocol Buffers are a way of encoding structured data in an efficient yet extensible format.”
Protocol Buffers were created by Google early in 2001, but not publically released until 2008.
An evolution of data:
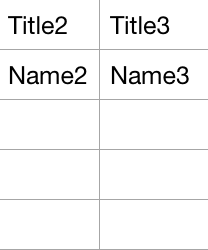
CSV (comma-seperated values) CSV is a simple file format used to store tabular data (For ex: database or spreadsheet). Here data fields are seperated by comma. For ex:
- Title1, Title2, Title3
- Name1, Name2, Name3
Create CSV file with text editor and enter the data just like above and save that file with extension .csv. Now open that file using Microsoft Excel or any spreadsheet editor. It would create a following data format.
Advantageous:
- Easy to read (Human readable format)
- Easy to edit
- CSV is processed by most of the existing applications.
Disadvantageous:
- There is no scheme enforced.
- Parsing is difficult if value contains comma.
- Most of the time types are inferred.
JSON(Javascript Object Notation) JSON is an another data format most frequently used. It is based on a subset of Javascript language. This format of data commonly used between server & web application. Most of the languages provides JSON parser these days. Ex:
{
“Name” : “Jacob”,
“Career” : “Teacher”
}JSON formats the data into Javascript objects and allows for key and value pairs.
Advantageous:
- Easy to share over the network.
- We can send whatever data inside JSON
- Human readable
Disadvantageous:
- There is no strict scheme enforced here. We can put whatever data inside JSON
- Big in size because of keys.
- Can’t add comments,documentations
- Not type safe.
How Protocol Buffer overcomes the drawbacks of both CSV and JSON(or XML).
Usually protocol buffer is defined by .proto text file. It imposes strict scheme based on available data types. Documents and comments can also be added. Here data will be automatically compressed which will optimize the bandwidth usage. It is also supported by most of the popular languages.
.proto format:


- syntax: The Proto version (or concept) used.
- Field Type: Specifies property types. Following scalar types are available.
double, int32, int64, uint32, uint64; sint32, sint64, fixed32, fixed64, sfixed32, sfixed64, bool, string, bytes
Here other than fixed scaler type (which consumes 4 or 8 bytes always), remaining types will be encoded with a variable size. String type usually contains UTF-8 encoded or 7-bit ASCII string value.
- Field Name: Specifies the property name. Each filed has a default value.
- Field Tag: Sequential numbered tag. This specifies the order of the serialization of all the fields for the message Person. Usually ordering of tag will not be altered. For protocol buffer Filed Name can be optional. It is the application that uses Filed Name for getting/setting the values.
Smallest Tag will start from 1 and largest tag can contain upto 536,870,91. We also can’t use tag number from 19000 to 19999, as these numbers are reserved for internal purposes.When messages are encoded, tags from 1 to 15 consumes 1 byte and tags from 16 to 2047 uses 2 bytes ans so on…
Other Primary collection types:
Protocol buffers also supports collection types like repeated (array or list type), maps **(usually dictionary types). In the above **Person message Filed Names like mobileNumbers & roles comes under this collection types.
How to add comments:
Protocol buffer supports both commenting as well as adding documentations. It supports both single & multi line comments. We can see both type of commenting from the above Person message.
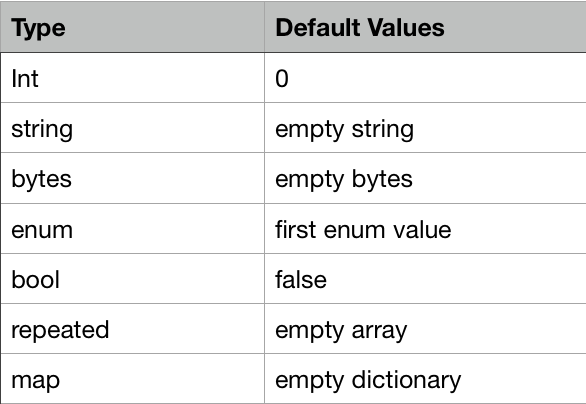
Default Values:
As discussed earlier, each field has a default values, until and unless no value is assigned. Default values will be different for each filed type
*There is no optional or required filed as of syntax proto3. One .proto file can contain multiple messages and even it supports nested messages. To access .proto file from different file, use `import “full path from the project root leve`l”*
How to maintain updates or versioning:
Proto file can be updated over the period of time based on new requirements. For example new fields can be introduced or even few fileds can be removed.
Scenerio 1 (forward compatible): Server has new (or updated) proto file. But client still uses old one. Here client silently ignores new fields as it doesn’t know about new fileds.
Scenerio 2 (Backward compatible): Server still sending old proto file. But clinet has an updated(new) proto file. Here client will use default values for new fields.
For the above two scenerio, make sure you will not modify existing filed tag. As said, you can freely modify filed names.
How to handle removing fields:
Scenerio 1: Server removed one field name and clinet doesn’t know this changes (as it is still using old proto file). Here client uses the default values for the removed fileds.
Scenerio 2: Server using old proto file and clinet using updated proto file. Here clinet will simple ignores the removed fields.
Reserving both field tag & field names:
As said earlier, proto file will evolve over the period of time. Few fileds may be deleted. Here it is good idea to reserve those deleted tags & names, so that new fileds will not reuse those reserved fields.(This scenerio happens when client still using old proto file and it doesn’t know anything about removed fields Here ultimate result will be corrupted data or application may crash). To reserve fields you can use following keywords:
reserved 1, 4, 10 to 15
reserved “firstName”
That’s it for now. I will be writing few advanced types in protocol buffer & how message will be encoded/decoded in the upcoming article. Thanks for reading!!!.

