

Deep Dive into MySQL Architecture: From Query to Hardware
Understanding how databases work under the hood is crucial for developers and system architects. In this comprehensive guide, we’ll explore the fascinating journey of a MySQL query, from the moment it leaves your application until it reaches the physical storage layer — with real-world examples at each step.
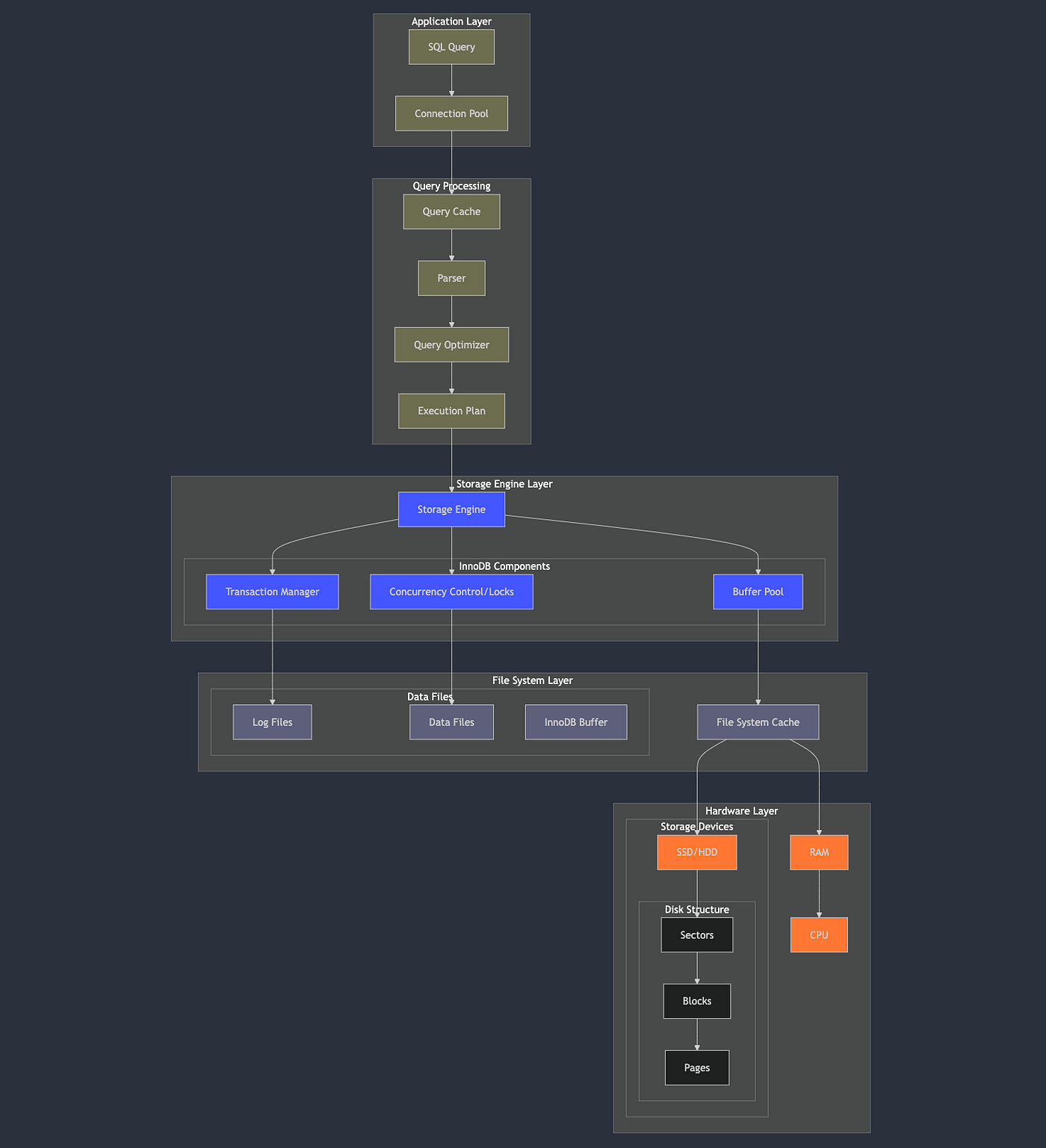
The Journey Begins: Application Layer
When your application executes a SQL query, it kickstarts a complex chain of events.
The first stop is the Connection Pool, a crucial component that manages and reuses database connections. Instead of creating a new connection for every query (which would be expensive), the pool maintains a set of pre-established connections, significantly reducing latency and resource overhead.
Let’s look at a typical connection scenario:
# Python example using connection pooling
from mysql.connector.pooling import MySQLConnectionPooldbconfig = {
"pool_name": "mypool",
"pool_size": 5,
"host": "localhost",
"user": "root",
"password": "password",
"database": "employees"
}
# Initialize the connection pool
connection_pool = MySQLConnectionPool(**dbconfig)
def get_employee(emp_id):
# Get connection from pool
connection = connection_pool.get_connection()
try:
cursor = connection.cursor()
cursor.execute("SELECT * FROM employees WHERE id = %s", (emp_id,))
return cursor.fetchone()
finally:
# Return connection to pool
connection.close()Without connection pooling, each query would need a new connection:
Time taken with new connection: ~100-300ms
Time taken with connection pool: ~5-20ms
Query Processing: Where the Magic Happens
Query Cache (Legacy Feature)
Deprecated in MySQL 5.7 and removed in MySQL 8.0
While deprecated in newer versions of MySQL, understanding the query cache helps grasp the evolution of database optimization. This component stored the results of SELECT queries along with their text. If an identical query arrived, MySQL could return the cached result instantly, bypassing all other processing steps.
Parser and Optimizer in Action
The parser is MySQL’s syntax checker and query validator. It breaks down your SQL query into a parse tree, ensuring all tables and columns exist and the query follows SQL grammar rules.
This tree then feeds into one of MySQL’s most sophisticated components: the Query Optimizer. The optimizer’s job is to transform your query into the most efficient execution plan possible.
It considers:
- Available indexes
- Table statistics
- Join ordering
- Access methods (table scans vs index lookups)
- Cost estimations for different execution strategies
The result is an execution plan that represents the optimal strategy for retrieving or modifying your data.
Let’s examine how MySQL optimizes a seemingly simple query
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
JOIN departments d ON e.dept_id = d.id
WHERE e.salary > 50000 AND d.location = 'New York';
Using EXPLAIN, we can see the optimizer’s decisions:
EXPLAIN SELECT e.first_name, e.last_name, d.department_name
FROM employees e
JOIN departments d ON e.dept_id = d.id
WHERE e.salary > 50000 AND d.location = 'New York'
+----+-------------+-------+------------+-------+---------------+-------------+---------+---------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+---------------------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | ref | PRIMARY,loc | loc_idx | 8 | const | 10 | 100.0 | Using where |
| 1 | SIMPLE | e | NULL | ref | dept_sal_idx | dept_sal_idx| 8 | employees.d.id | 100 | 20.0 | Using where |
+----+-------------+-------+------------+-------+---------------+-------------+---------+---------------------+------+----------+-------------+
The optimizer chose to:
- First access departments table using location index
- Then join with employees using a composite index on (dept_id, salary)
- Use index condition pushdown for salary filtering
Storage Engine Layer: InnoDB in Action
The storage engine layer is where logical operations transform into actual data manipulation. InnoDB, MySQL’s default storage engine since version 5.5, implements several crucial components:
Buffer Pool Management
The buffer pool is InnoDB’s secret weapon for performance. It’s an in-memory cache that stores:
- Frequently accessed data pages
- Index pages
- Internal data structures
- Insert buffers
By keeping hot data in memory, InnoDB dramatically reduces disk I/O, often the biggest bottleneck in database performance.
Let’s examine buffer pool behavior with a real example:
-- Check buffer pool status
SHOW ENGINE INNODB STATUS;
-- Key metrics from output:
Buffer pool size 655280 pages
Free buffers 1018
Database pages 593118
Old database pages 218923
Modified db pages 79292
Example of buffer pool impact:
-- First query (cold cache)
SELECT * FROM large_table WHERE id = 1000;
-- Time: 150ms (disk read required)
-- Second query (warm cache)
SELECT * FROM large_table WHERE id = 1000;
-- Time: 0.2ms (data in buffer pool)Transaction Manager and Concurrency Control
These components ensure the ACID properties (Atomicity, Consistency, Isolation, Durability) that make databases reliable:
- Transaction manager handles commits and rollbacks
- Lock manager prevents conflicting operations
- MVCC (Multi-Version Concurrency Control) allows consistent reads without locking
Here’s how MVCC handles concurrent transactions:
-- Session 1
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- Session 2 (runs simultaneously)
SELECT balance FROM accounts WHERE id = 1;
-- This reads the OLD version of the row
-- Session 1
COMMIT;
-- Now Session 2 will see the new version
File System Layer: Bridging Logic and Physics
The file system layer is where logical database operations translate into physical storage operations. It manages:
Data Files Structure
Here’s what MySQL’s data directory looks like:
/var/lib/mysql/
├── employees/
│ ├── employees.ibd # Table data file
│ ├── departments.ibd # Table data file
│ └── salaries.ibd # Table data file
├── ib_logfile0 # Redo log
├── ib_logfile1 # Redo log
├── ibdata1 # System tablespace
└── undo_001 # Undo tablespace
- `.ibd` files: Tables and indexes
- Redo logs: Transaction recovery
- Undo logs: Transaction rollback
- System tablespace: Data dictionary and undo logs
Example of how data is written:
INSERT INTO employees (id, name, salary) VALUES (1, 'John', 50000);
-- This triggers:
1. Write to undo log (in case of rollback)
2. Write to redo log (for crash recovery)
3. Update in buffer pool
4. Eventually flush to employees.ibd
Hardware Layer: The Physical Foundation
At the lowest level, we reach the hardware components that physically store and process our data:
Storage Devices
Whether SSDs or HDDs, storage devices organize data in a hierarchy:
- Sectors: The smallest physical storage unit
- Blocks: Groups of sectors
- Pages: The unit of data transfer between disk and memory
CPU and RAM
The CPU executes all database operations, while RAM hosts:
- Buffer pool
- Query cache
- Sort buffers
- Join buffers
- Other in-memory structures
Storage Performance Examples
Different storage types impact performance:
Query: SELECT * FROM employees WHERE id BETWEEN 1000 AND 2000;
Performance on different storage:
HDD (random read): ~100 IOPS
- Time taken: ~500ms
SSD (random read): ~10,000 IOPS
- Time taken: ~50ms
NVMe (random read): ~100,000 IOPS
- Time taken: ~5ms
Memory hierarchy impact:
Data access times:
L1 Cache: ~1ns
L2 Cache: ~4ns
RAM: ~100ns
SSD: ~100,000ns (0.1ms)
HDD: ~10,000,000ns (10ms)
Practical Optimization Examples
1. Buffer Pool Optimization
In order to check if buffer pool is used efficiently or needs optimisation always check the buffer pool hit rate.

SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_read_requests';
+----------------------------------+---------------+
| Variable_name | Value |
+----------------------------------+---------------+
| Innodb_buffer_pool_read_requests | 3448977082957 |
+----------------------------------+---------------+
SHOW GLOBAL STATUS LIKE 'innodb_pages_read';
+-------------------+-------------+
| Variable_name | Value |
+-------------------+-------------+
| Innodb_pages_read | 55592980173 |
+-------------------+-------------+
-- Hit rate: 98.3%
-- Good hit rate: > 95%
Above is the hit rate of Nuclei’s Consolidated Slave DB. This database is a read slave as well as used for business/analytics queries.
2. Query Optimization
-- Bad query -- full table scan
SELECT * FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE YEAR(o.order_date) = 2024;
-- Optimized query -- range scan
SELECT * FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE o.order_date >= '2024-01-01'
AND o.order_date < '2025-01-01';
-- Performance difference can be 10-100x
Wrapping it up
MySQL’s architecture is a masterpiece of software engineering, combining decades of database theory with practical optimizations. Each layer serves a specific purpose, working in harmony to provide the performance, reliability, and functionality that modern applications demand.
The examples above demonstrate how understanding these internals can lead to better:
- Query optimization
- Server configuration
- Performance troubleshooting
- Capacity planning
For instance, knowing that the buffer pool is crucial for performance might lead you to:
- Increase buffer pool size to match working set
- Monitor buffer pool hit rate
- Organize queries to maximize buffer pool usage
- Plan server RAM requirements accordingly
This article aims to provide a high-level overview of MySQL’s architecture with practical examples. Many components have additional complexity and nuance beyond what’s covered here. For specific implementation details, always refer to MySQL’s official documentation.
RELATED ARTICLES



Get a free consultation on Segmentation strategy and
Ecosystem practices
