Data is any fact, figure or any information that we use or store or communicate. In essence, data is everywhere, your click on your mobile screen or you asking Alexa to set an alarm, what cashbacks/rewards you have availed, and so on and on.
While working with data we essentially have to do three steps:
- Extract data from source (E)
- Transform to desired format (T)
- Load to desired destination (L)
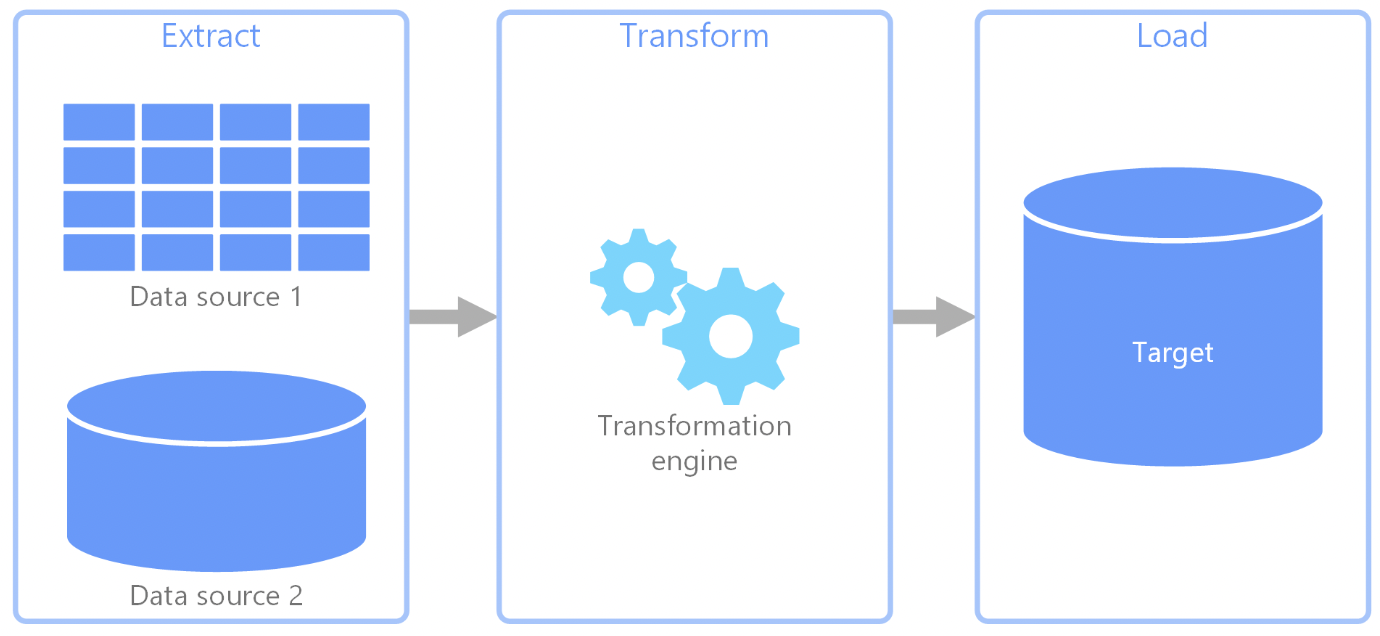
(Source)
First let us understand a few problems that one might encounter while working with data.
1. The amount of data that is being collected
With the abundance of data intensive applications, the amount of data produced is huge. Applications collect data for every interaction and events. Manually working with these large datasets becomes too tiresome and impossible in some cases.
2. Collecting data from multiple sources
Different pieces of required information are often present in different sources. One has to club data coming from multiple sources to get useful information. A lot of resources/infrastructure are spent providing secure and reliable connection to these sources. Whole code and packages/libraries have to be written for writing (producing) as well as reading (consuming) from another service in a reliable and resilient way.
3. Different formats of data from different sources
Multiple applications use their data in their own customized way. Thus sharing data between different sources leads to discrepancy in data formats. Data has to be transformed in the route between source and destination.
4. Lots of noise in the data
The data that is not relevant for the use case or that does not possess any significant information is noise. These large datasets contain huge amounts of noises as well. All of the data is not valuable for any application. Noises have to be removed for providing visibility for the required data.
5. Writing complex and long codes for data transformation
Huge amounts and different formats of data overwhelms the person working on it. One has to write large number of lines of code to:
- Build a resilient and reliable data system
- Handle and transform different formats
Now that we have understood how painful it is to work with large amounts of non uniform data, let us see what NiFi has in store to solve these problems.
NiFi is built for the purpose to easily and efficiently automate the data flow from source to destination.
NiFi is a powerful tool that can be used to automate, schedule, transform data, send alerts and so on and on and on. It enables to create extensive data flows in an intuitive easy to use format.
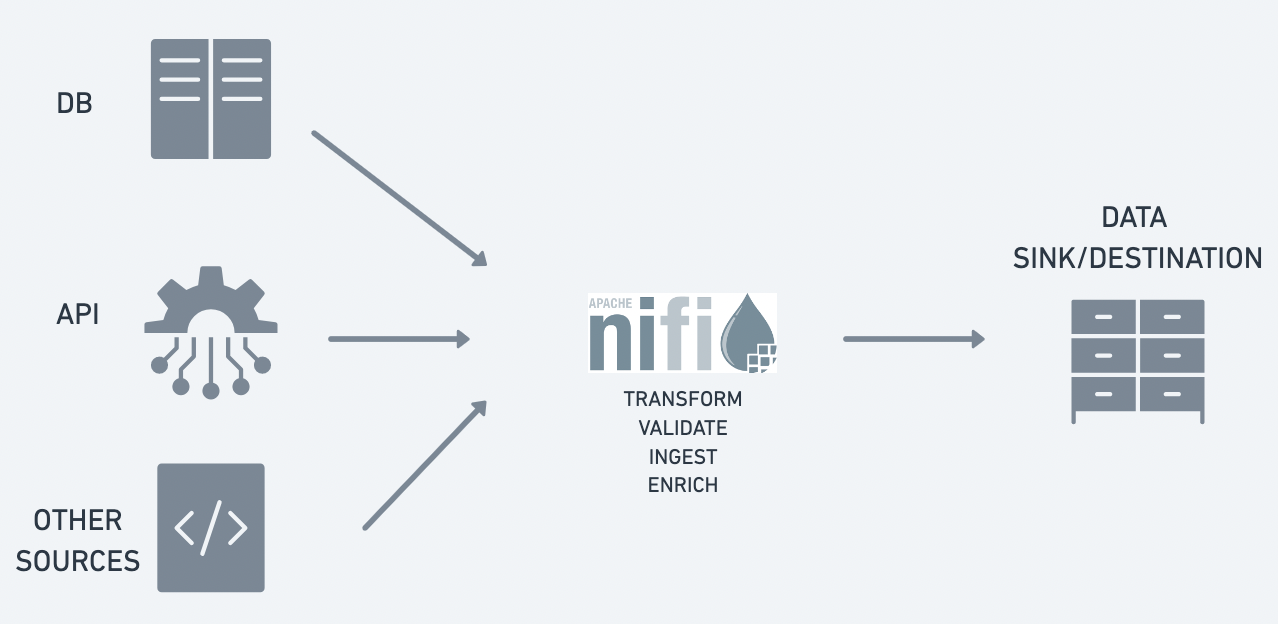
1. Built to handle large amounts of data
There is no restriction on data size when working with NiFi (only our infrastructure should be configured to handle large volumes of data). NiFi is designed to move large amounts of data. It also provides features like load balancing the data, prioritized queuing while moving data from one processor to another.
2. Provide large number of processors
NiFi provides 288 (as of 1.12.1 version) number of processors to perform different sets of transformations, thus making it a powerful tool that can handle almost all the use cases of data transformation. From taking a file from a local system to dumping the data into the azure buckets, all are covered with NiFi.
3. Easy to build, and easy to debug
NiFi provides an easy to use interface with simple drag and drop features to build data flow. A data transformation that can take hundreds of lines of code can be built by using a couple of processors without writing any code. For example: a simple validation of each row of a csv file can be done with 3 processors:
- Picking up the data from source
- Validating content of csv file by using CSVValidator processor
- Dumping into the destination
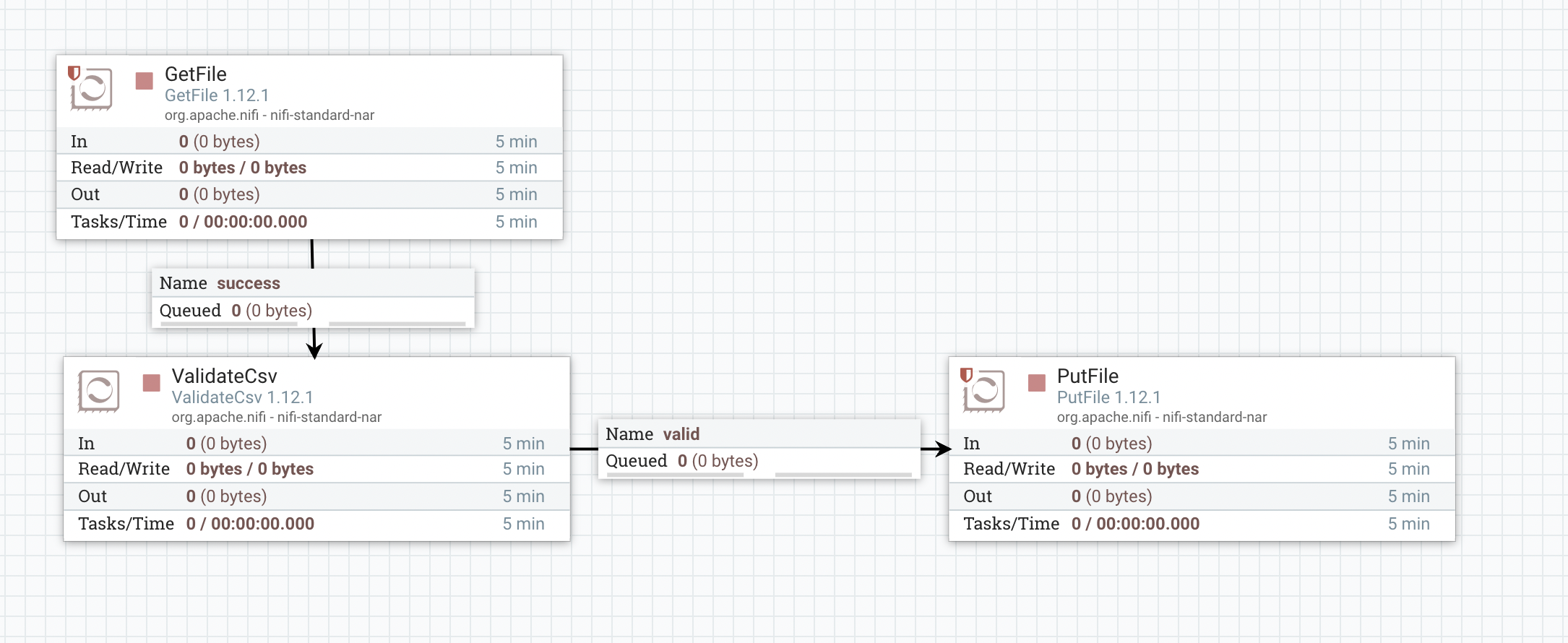
With the help of different processors every transformation is isolated, thus making it possible to debug a part of the system without restarting the whole flow or stopping the complete data flow. The contents that are transformed from one processor to another can be viewed in the queue.
4. Easy to connect with multiple sources
NiFi provides a number of processors and controller services to connect with a large number of data sources. Instead of writing code and using libraries to provide secure and robust connection with multiple third party software, NiFi provides ready to use processors, where we just have to enter basic configuration for connection and voila, connection successfully and securely created.
5. Provides a secure system
NiFi provides secure flow of data at every step. It uses 2-way SSL for all machine-to-machine communication. It itself hides all the sensitive properties of any processor. It also provides features to allow multiple user access.
How we are using NiFi at Nuclei
1. Data In Nuclei
Nuclei deals heavily with transaction data coming from merchant SDK. Reconciliation data between multiple parties (bank, merchants, nuclei) produce everyday and have to be managed and sent to different destinations in different formats. For some banks, payments are supported by a file based system, leading to generation of payment files on a daily basis. User interaction data extracted from user activity on Nuclei SDK in the bank’s application. Etc All these are large datasets, and have to be stored, managed, transformed, and perform ETL on Nuclei’s premise.
2. NiFi Deployment
NiFi is deployed on Nuclei’s premise on kubernetes with the help of the cetic helm chart. Deploying on kubernetes provides the advantages of:
- Reduction of complexity and time of deployment, providing streamline delivery of updates
- Increased scalability and accessibility
3. NiFi Registry
Nifi Registry is an add -on application that provides a central location for storage and management of nifi’s data. Nuclei uses NiFi Registry to store all the data flows developed in the NiFi dashboard. It acts like a Git repository for all pipelines and helps in version control of the data flows. Different registries are maintained for different development environments.


